
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 테일러 급수
- 백준
- alembic
- 백엔드
- 강한 연결 요소
- sqlalchemy
- api서버
- 구성적
- 취업
- 가우스 소거법
- C언어
- 웹서버
- flask
- 아파치
- FastAPI
- 리트코드
- 알고리즘
- 이분 탐색
- 위상 정렬
- scc
- 파이썬
- 개발자
- 신입
- BFS
- 수학
- python
- MYSQL
- 데이터베이스
- Django
- SQL
- Today
- Total
Devlog
[알고리즘] 강한 연결 요소(2): 타잔 알고리즘 본문
강한 연결 요소 (Strongly Connected Component) 시리즈
1. 코사라주 알고리즘
2. 타잔 알고리즘
3. 2-SAT

소개
지난 챕터 에서는 코사라주 알고리즘의 소개와 증명에 대해서 설명했습니다. 코사라주 알고리즘은 정방향/역방향 이렇게 DFS를 두번 돌려서 SCC를 구하는 방식으로, 구현은 간단하지만 DFS를 두번 돌려야 하고, 그렇기에 코드가 약간 긴 편입니다. 그러나 타잔 알고리즘은 DFS를 단 한번 실행함으로써 모든 존재하는 SCC를 구하게 됩니다. 비록 이해 난이도는 코사라주보다 조금 어렵지만, 코드량이 적은 편이라 응용 문제에서도 쉽게 활용할 수 있는 알고리즘 입니다. 코드는 아래 블로그를 참고해서 파이썬으로 옮겨적었습니다. 코사라주 때는 그냥 알고리즘만 보고 바로 코딩했는데, 이건 다른 분이 작성하신 코드를 참고해서 파이썬으로 옮겨적었습니다.(아래 블로그) 확실히 타잔이 코라사주보다는 어렵긴 하네여
26. 강한 결합 요소(Strongly Connected Component)
강한 결합 요소란 그래프 안에서 '강하게 결합된 정점 집합'을 의미합니다. 서로 긴밀하게 연결되어 있다고...
blog.naver.com
알고리즘

0을 방문했습니다. 방문한 0을 stack에 집어넣고 0에 고유 id를 생성합니다. 이 고유 아이디는 다른 노드를 방문하면 id값을 올려서 방문한 노드에 추가합니다.

이렇게 해서 0 -> 2- > 5순으로 방문했습니다. 이제 3이 아닌 8로 진행해 보겠습니다.

8 -> 4 -> 6 으로 진행했습니다. 6위치에서 8로 검색을 시도하려고 합니다.
8은 이미 탐색이 되었습니다. 또한 8은 아직 SCC로 결정이 나지 않았습니다. 결정이 나지 않았다는 것은 8 -> 4 -> 6은 서로 사이클이라는 것을 의미합니다. 즉 8 -> 4 -> 6은 SCC로 이루어 질 수 있기 때문에 stack의 가장 윗부분이 8이 될 때 까지 전부 빼내서 SCC 리스트에 담습니다.
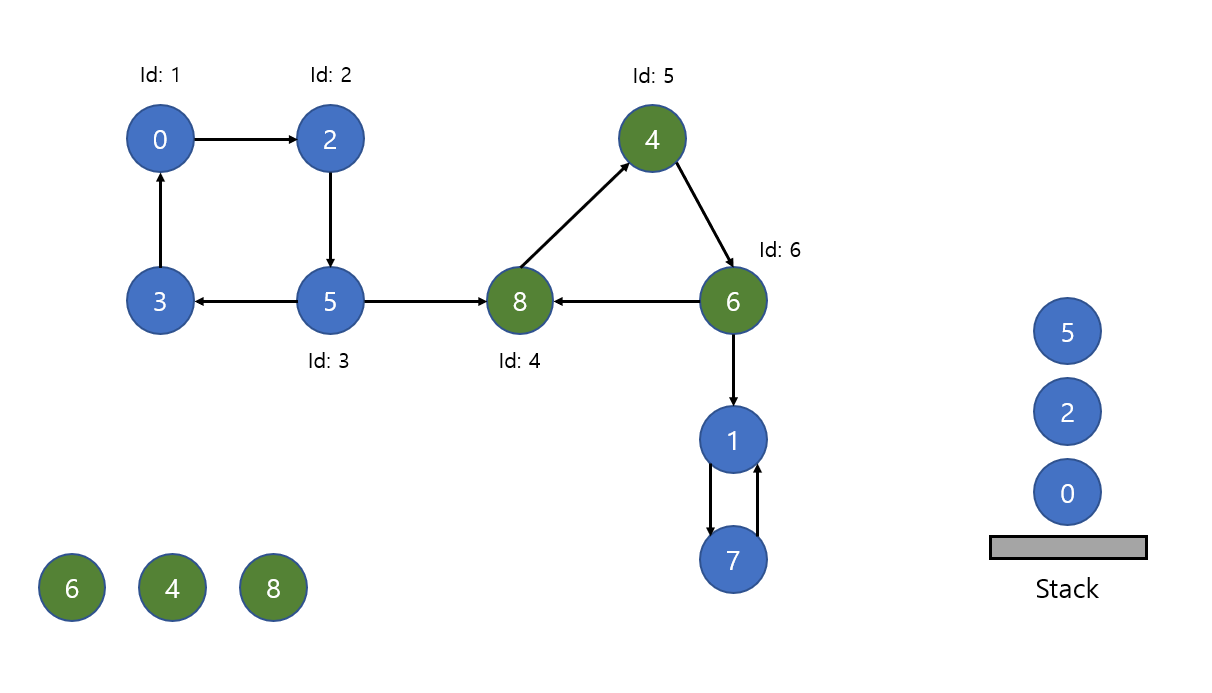
6, 4, 8은 이제 SCC로 결정이 되었습니다. 현재 탐색 위치는 6입니다. 8방향으로 이미 시도를 했기 때문에 1로 이동합니다.
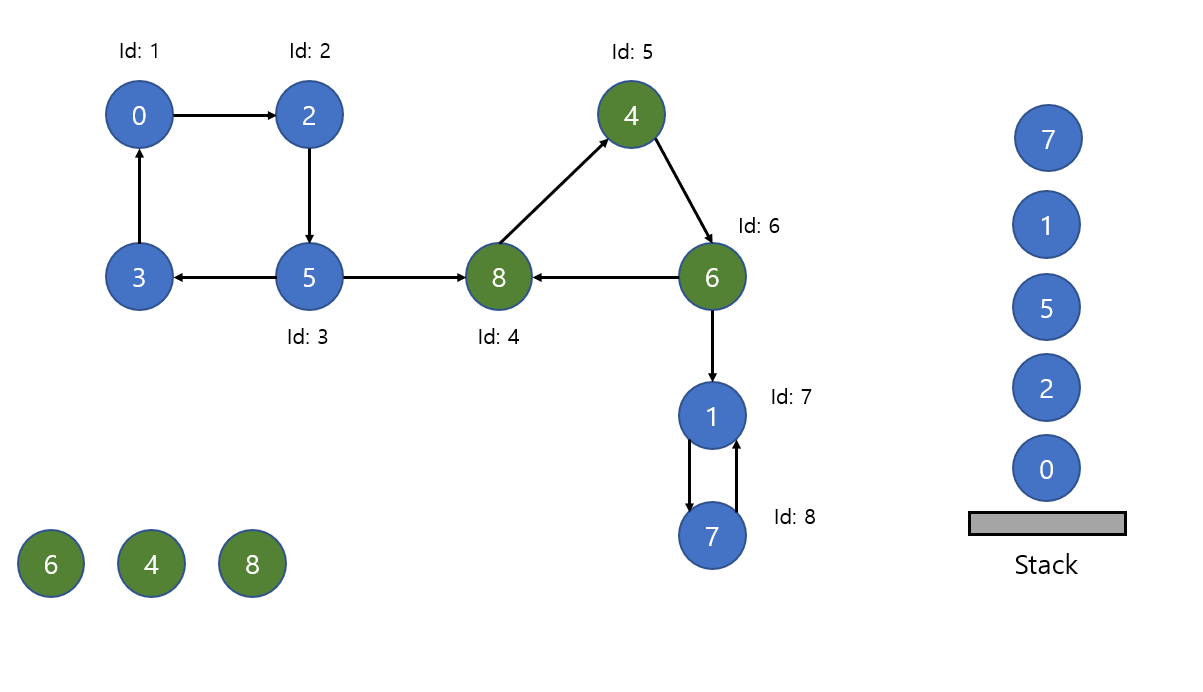
7까지 이동했습니다. 7위치에서 1로 탐색을 시도하려고 하는데 1은 SCC로 결정나지 않았지만 또한 이미 탐색이 되어 있는 상태 입니다. 결국 1 -> 7도 서로 사이클이기 때문에 SCC로 결정이 되고 stack의 맨 위의 데이터가 1이 될 때 까지 전부 빼냅니다.

1, 7을 SCC로 결정했습니다. 1에서는 더이상 탐색할 만한 노드가 없기 때문에 뒤로 돌아갑니다. 6, 4, 8도 마찬가지로 더이상 탐색할 노드가 없기 때문에 5로 되돌아 갑니다.
5에서는 아직 탐색이 되지 않은 3이 남아있습니다. 3으로 이동해 봅니다.

3에서 0으로 이동할 수 있는데 0은 이미 탐색이 되었지만 SCC로 결정이 되지 않았기 때문에 이들은 SCC로 결정이 됩니다. 아까와 같은 방식으로 진행합니다.

이렇게 모든 강한 연결 요소를 찾았습니다.
코드 설명
알고리즘에 사용되는 전역 변수들은 다음과 같습니다.
def scc(G, V):
finished = [False] * (V+1)
label = [0] # 누적 라벨: 노드를 한번 방문할 때마다 1씩 증가
labels = [0] * (V+1) # 고유 라벨 번호 저장
ans, s = [], []
def _scc(u)finished: 해당 노드가 SCC로 결정이 되었는지에 대한 여부 입니다,
label: 현재 라벨(아이디) 번호 입니다. 새로운 노드를 방문할 때마다 인덱스0의 값이 1 씩 올라갑니다. 이렇게 진행하면 각 노드에 고유의 라벨을 붙일 수 있습니다.
labels: 라벨 번호 리스트 입니다. 예를 들어 노드 0의 라벨번호를 확인하고 싶으면 labels[0]을 작성하면 됩니다.
s: 스택 입니다.
def _scc(u): 실제로 작동하는 SCC 알고리즘 입니다. 인자값으로 노드 번호가 들어갑니다.(라벨 번호 아님)
def _scc(u):
label[0] += 1
parent = labels[u] = label[0] # 자기 자신이 부모노드로 가정
s.append(u)처음 u에 방문했을 때에 대한 처리 입니다. label번호를 1 증가사키고, 이 리벨 번호를 labels에 등록한 다음 parent에도 대입합니다. 즉, 루트(또는 부모)노드가 자기 자신이라고 가정을 하면서 시작하는 것입니다. 이 parent가 바뀌게 되는 시점은 SCC로 결정이 될 사이클을 발견했을 경우 입니다. 이 때 parent는 SCC중 가장 처음방문한 노드의 라벨 번호로 바뀝니다. 방문을 했기 때문에 stack에 해당 노드를 추가합니다.
for v in G[u]:
if not labels[v]:
# 아직 방문 X
parent = min(parent, _scc(v))
elif not finished[v]:
# 방문은 했었으나 SCC 처리가 아직 안된 노드 = 사이클
parent = min(parent, labels[v])
if parent == labels[u]:
# 자기 자신이 사이클 중 가장 먼저 탐색되었다
# = 루트 노드
scc_set = []
while s:
p = s.pop()
scc_set.append(p)
finished[p] = True
if u == p:
break
ans.append(scc_set)
return parent하위 노드들을 탐색합니다.
하위 노드의 라벨이 0 (if not labels[v])라는 것은 아직 탐색 조차도 안했다는 의미 입니다. 따라서 하위 노드를 탐색 합니다. 위에도 설명했지만 parent가 바뀌게 되는 시점은 사이클을 만났을 경우 인데 그냥 대입이 아닌 min을 사용한 이유는, parent는 항상 SCC 중 맨 처음 발견한 노드, 즉 라벨 값이 더 작은 노드로 시작하기 때문입니다. 반대로 사이클을 마주하지 않은 채 _scc()가 리턴이 되었다면 이때의 label값은 parent보다 더 크게 됩니다. 즉, 하위의 노드와 현재 위치의 노드는 서로 SCC가 아니라는 의미가 됩니다.
사이클을 발견했을 때가 바로 밑줄의 elif not finished[v] 입니다. 정확히는 labels[v] and not finished[v]로 탐색을 되어 있지만 아직 SCC가 확정이 되지 않은 노드를 발견 즉, 사이클을 발견한 것입니다. 그렇다면 위에서 설명한 대로 이 라벨 값은 항상 parent보다 작기 때문에 min()을 쓸 필요가 없지 않느냐 하는 의문이 제기되겠지만 이에 대한 반례가 존재합니다.

위의 그림 처럼 1 -> 2 -> 3 -> 4 순으로 탐색했다고 가정합니다. 4위치에서는 0은 사이클로 판단을 했기 때문에 0의 아이디 값인 1을 리턴합니다. 위로 올라가 3에서도 _scc(4)가 1을 리턴했기 때문에 parent = min(3, 1) = 1이 됩니다. 마찬가지로 2에서도 마찬가지로 parent=1이 됩니다. 이렇게 거슬러 올라가 _scc(1)로 다시 도착하게 됩니다.

하지마 아직 _scc(1)에서는 2로 가는 간선 말고 4로 가는 간선이 하나 더 있습니다. stack의 데이터를 전부 빼내서 SCC 처리하는 것은 _scc(1)이 간선 탐색을 끝내고 나서 작업하기 때문에 finished[4]는 false가 됩니다. 따라서 elif조건문에 걸리게 되고 이 때 labels[v]는 4가 됩니다. min()을 쓰지 않게 되면 parent가 이미 1로 결정이 났음에도 불구하고 4로 다시 덮어씀으로써 4를 리턴하게 됩니다.
_scc(1)에서 SCC 처리를 하려면 현재 위차하고 있는 노드의 label_id와 parent_id가 일치해야 합니다(순환). 즉, 여기에서는 parent_id가 1이 되어야 하는데, 지금 상황에서는 parent_id가 4로 덮어씌여졌기 때문에 SCC처리 조건을 만족하지 못해 결국 SCC 인식을 하지 못하게 됩니다.
if parent == labels[u]:
# 자기 자신이 사이클 중 가장 먼저 탐색되었다
# = 루트 노드
scc_set = []
while s:
p = s.pop()
scc_set.append(p)
finished[p] = True
if u == p:
break
ans.append(scc_set)
return parentSCC 요소들을 수집하는 코드 입니다. if parent == labels[u]는 자기 자신의 부모인 경우, 즉 루트 노드인 경우에만 SCC를 수집합니다. 그렇기 때문에 스택에서 추출된 값이 자신과 동일 (u==p)할 때 까지 요소들을 꺼내서 수집합니다.
전체 코드
2150번: Strongly Connected Component
첫째 줄에 두 정수 V(1 ≤ V ≤ 10,000), E(1 ≤ E ≤ 100,000)가 주어진다. 이는 그래프가 V개의 정점과 E개의 간선으로 이루어져 있다는 의미이다. 다음 E개의 줄에는 간선에 대한 정보를 나타내는 두 정
www.acmicpc.net
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10**7)
def scc(G, V):
finished = [False] * (V+1)
label = [0] # 누적 라벨: 노드를 한번 방문할 때마다 1씩 증가
labels = [0] * (V+1) # 고유 라벨 번호 저장
ans, s = [], []
def _scc(u):
label[0] += 1
parent = labels[u] = label[0] # 자기 자신이 부모노드로 가정
s.append(u)
for v in G[u]:
if not labels[v]:
# 아직 방문 X
parent = min(parent, _scc(v))
elif not finished[v]:
# 방문은 했었으나 SCC 처리가 아직 안된 노드 = 사이클
parent = min(parent, labels[v])
if parent == labels[u]:
# 자기 자신이 사이클 중 가장 먼저 탐색되었다
# = 루트 노드
scc_set = []
while s:
p = s.pop()
scc_set.append(p)
finished[p] = True
if u == p:
break
ans.append(scc_set)
return parent
for e in range(1, V+1):
if not labels[e]:
_scc(e)
return ans
V, E = map(int, input()[:-1].split())
G = [list() for _ in range(V+1)]
for _ in range(E):
u, v = map(int, input()[:-1].split())
G[u].append(v)
ans = scc(G, V)
for e in ans:
e.sort()
ans.sort(key=lambda e: e[0])
print(len(ans))
for e in ans:
res = ''
for _e in e:
res += str(_e) + ' '
res += '-1'
print(res)마치며
코사라주에 비해 타잔 알고리즘은 단 한번의 DFS로 모든 SCC를 구했습니다. 타잔 알고리즘의 매커니즘은 방문 여부를 두 가지를 사용했다는 점인데, 하나는 탐색을 시작하자마나 식별자를 지정하는 labels와 SCC가 처리된 여부 finished두 개 를 사용했다는 점입니다. 하위 노드의 label이 적혀있지 않으면 아직 탐색을 하지 않은 노드, label은 적혀있는데 finished가 False인 경우는 사이클로 판단하여 SCC처리를 해 주었습니다.
다음 챕터에서는 SCC를 바탕으로 여러 논리식을 다루는 2-sat에 대해서 설명할 예정입니다.
'Problem Solving > 알고리즘' 카테고리의 다른 글
| [알고리즘] 이분 탐색의 변종들 (1) - lower/upper bound를 알아보자 (0) | 2023.03.26 |
|---|---|
| [알고리즘] 강한 연결 요소(1): 코사라주 알고리즘 (0) | 2022.05.31 |
| [알고리즘] 위상 정렬 (정리) (0) | 2022.05.19 |

