
Devlog
[알고리즘] 이분 탐색의 변종들 (1) - lower/upper bound를 알아보자 본문
이분탐색
알고리즘 공부를 어느정도 해봤다면 누구에게나 친숙한 알고리즘 입니다. 정렬된 배열에서 특정 값의 위치(인덱스 값)을 찾는 알고리즘이지요. 이분탐색을 구현하는 코드는 아래와 같습니다. 해당 값이 존재하면 그 값에 대한 인덱스 값을 출력하고, 없으면 -1을 출력합니다.
int process_binary_search(vector<int>& arr, int e)
{
int n = (int)arr.size();
int left = 0, right = n-1, mid;
while(left <= right) {
mid = (left + right) >> 1;
if(arr[mid] == e)
return mid;
else if(arr[mid] > e)
right = mid - 1;
else
left = mid + 1;
}
return -1;
}
이분탐색의 알고리즘은 선택된 값(arr[mid])이 찾고자 하는 값(e)과 일치하면 그 인덱스 값을 리턴하고(mid), 그렇지 않은 경우, 범위를 계속 좁혀가며 계속 선택된 값과 찾고자 하는 값이 일치한 지 확인합니다. left와 right가 일치하는 순간까지도 일치하는 값이 없다면, 찾고자 하는 값이 없는 것으로 간주하고 -1을 리턴합니다.
이분 탐색은 조금만 생각을 잘 해도 금방 이해할 수 있고 또, 구현도 금방 할 수 있습니다. 하지만, 코딩 문제 또는 중급 이상의 알고리즘에서는 순수 이분탐색 보다는 lower bound, upper bound라는 이분 탐색의 변종을 사용하는 경우가 많습니다. 그리고 이 친구들은 로직을 잘 이해하지 못하면 구현할 때 많이 헷갈릴 수 있습니다. 이번 포스트에서는 upper bound와 lower bound의 소개와 구현 방법, 그리고 이를 활용하는 예제 문제, 또는 알고리즘에 대해서 간단하게 설명하려고 합니다.
Upper Bound
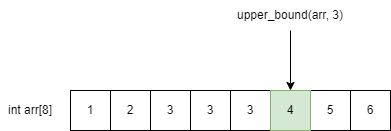
upper_bound란 찾고자 하는 값 보다 더 큰 값의 첫 번 째 위치를 구하는 알고리즘 입니다. 예를 들어 [1,2,3,3,3,4,5,6]가 있으면, 3에 대해 upper_bound를 수행하면 4가 더 큰 값의 첫 번 째 위치해 있는 값이기 때문에 4의 인덱스 값인 5가 출력이 됩니다. 구현은 기존 이분 탐색에서 조금 만 바꿔주면 됩니다. 어떻게 바꿔줘야 할까요?
아까 작성했던 이분 탐색의 코드를 다시 한번 보고 생각을 해 봅시다.
while(left <= right) {
mid = (left + right) >> 1;
if(arr[mid] == e)
return mid;
else if(arr[mid] > e)
right = mid - 1;
else
left = mid + 1;
}이분 탐색에서는 같으면 바로 인덱스 리턴, 크면 right를 mid-1 왼쪽으로 땡기고, 작으면 left를 mid+1으로 땡겼습니다. 이런 식으로 찾고자 하는 값에 대한 인덱스를 구했습니다. 하지만 upper bound에서는 찾고자 하는 값이 아닌 그 값보다 더 큰 첫번 째 값의 위치를 구해야 합니다.
그렇기 때문에 arr[mid]가 e보다 일치하다고 해서 바로 리턴해서는 안됩니다. 무조건 e보다 더 커야 하기 때문에 다음 arr[mid]는 이전 값보다 더 커야 합니다. 따라서 arr[mid] == e 일 때 left를 mid + 1으로 땡겨야 합니다. e보다 작을 때도 마찬가지로 left = mid + 1로 잡아놔야 합니다.
arr[mid]가 e보다 큰 경우를 생각해 봅시다. 이분 탐색에서는 이런 일이 일어나면 애초에 답이 아니기 때문에 arr[mid]보다 더 작은 값으로 접근할 수 있게 mid - 1로 땡겼습니다. 하지만 upper bound에서는 무조건 e보다 더 커야 하기 때문에 e보다 더 큰 arr[mid]값이 정답이 될 수도 있습니다. 따라서 이때 left를 mid + 1이 아닌 mid로 땡깁니다.
int process_upper_bound(vector<int>& arr, int e)
{
int n = (int)arr.size();
int left = 0, right = n-1, mid;
while(left < right) {
mid = (left + right) >> 1;
if(arr[mid] > e) {
right = mid;
} else {
left = mid + 1;
}
}
return right;
}Lower Bound

lower bound는 찾고자 하는 값이 여러개 있을 때, 이 중 가장 맨 왼쪽에 있는 인덱스 값을 구하는 알고리즘 입니다. 찾고자 하는 값이 없다면 upper_bound처럼 해당 값보다 더 큰 첫번 째 값의 위치를 리턴합니다. upper_bound와 비슷한 접근 법으로 알고리즘을 구현할 수 있습니다.
찾고자 하는 값이 여러개 있을 때, 이 중 가장 맨 왼쪽에 있는 인덱스 값을 구하는 알고리즘이라는 말에 집중해 봅시다. 이 말은 즉슨, 같은 값을 찾았더라도 여기서 끝이 아니라 더 왼쪽에 같은 값이 있는 지 찾아야 한다는 말이 됩니다. 따라서 arr[mid] == e일 때 return하는 것이 아닌, 좀 더 왼쪽으로 가야 하므로 right를 mid로 땡겨야 합니다. 여기서 주의해야 할 점은 같은 값들 중 가잔 왼쪽에 있는 인덱스를 찾는 것이지 해당 값보다 더 작은 값의 위치를 찾는 것이 아니므로 right = mid - 1이 아닌 right = mid가 되어야 합니다.
arr[mid] > e, 즉 찾고자 하는 값보다 arr[mid]가 더 큰 경우 입니다. 말 그대로 lower하기 때문에 right = mid - 1로 보일 수 도 있겠지만, 해당 값이 존재하지 않으면, 해당 값보다 더 큰 값이 정답이 됩니다. 따라서 큰 값이 답이 될 수도 있기 때문에 arr[mid] == e 처럼 right = mid로 잡아놔야 합니다.
arr[mid] < e 의 경우 즉, 찾고자 하는 값보다 arr[mid]가 더 작은 경우 입니다. e보다 더 작은 값을 찾으라는 말이 없기 때문에 left를 mid + 1로 땡깁니다.
int process_lower_bound(vector<int>& arr, int e)
{
int n = (int)arr.size();
int left = 0, right = n-1, mid;
while(left < right) {
mid = (left + right) >> 1;
if(arr[mid] >= e) {
right = mid;
} else {
left = mid + 1;
}
}
return left;
}끗!
오늘 포스트는 여기서 끝이지만, 아직 완전한 끝은 아닙니다. lower/upper bound 활용 문제와 알고리즘, 그리고 이분탐색과 비슷하지만 비슷하지 않은 것 같은 매개변수 탐색 (Parametric Search) 등, 아직 하고 싶은 말이 많지만, 지금 술 먹고 새벽 4시 까지 이 글을 쓰고 있기 때문에 너무 졸려서 이제 쉼표를 찍고 자려고 합니다. 다음 포스트에서는 매개변수 탐색 대해서 설명하려고 합니다. 그럼 ㅃㅃ
'Problem Solving > 알고리즘' 카테고리의 다른 글
| [알고리즘] 강한 연결 요소(2): 타잔 알고리즘 (8) | 2022.07.02 |
|---|---|
| [알고리즘] 강한 연결 요소(1): 코사라주 알고리즘 (0) | 2022.05.31 |
| [알고리즘] 위상 정렬 (정리) (0) | 2022.05.19 |

